Puffin: Deep-learning-inspired explainable sequence model of transcription initiation
Puffin is an interpretation-focused sequence model for transcription initiation in the human genome which is also applicable to other mammalian species. Puffin can predict basepair-resolution transcription initiation signals using only genomic sequence as input, and more importantly, analyze the sequence basis of any transcription start site (TSS) at motif and basepair levels.
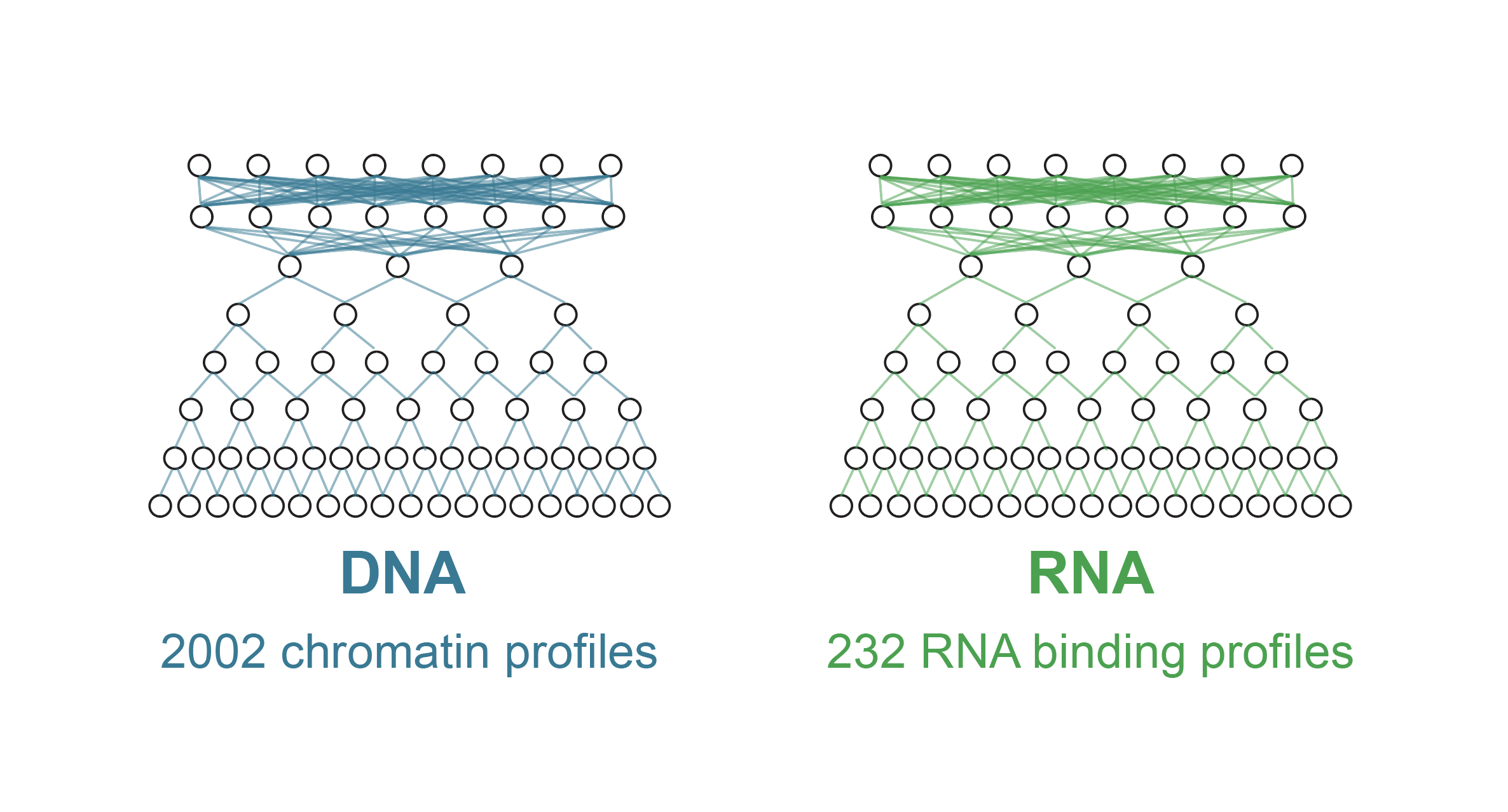
Puffin-D is a prediction-focused deep learning sequence model for basepair-resolution transcription initiation signals. Puffin-D takes 100kb input and accurately predicts the transcriptional signal strength. The prediction-focused deep learning model Puffin-D is available at puffind.zhoulab.io.
For most use cases, we recommend the interactive Puffin web server at puffin.zhoulab.io. The prediction-focused deep learning model Puffin-D is available at puffind.zhoulab.io.
GitHub repository | Webserver | Manuscript | Manuscript repo